
Battle of the LLMs Part 2: Can they code and judge themselves?


In the first experiment, I tested whether LLMs could act as code reviewers, asking them to define a rubric for high-quality code and then critique a given implementation based on their own criteria. Some models excelled at structured feedback, others were too vague, and a few lacked the depth we expect from a seasoned software engineer.

Now, I’m flipping the test. Instead of just reviewing code, the LLMs have to write the code themselves.
The challenge? Implement a prefix calculator in Go.
Each LLM was given the same prompt and asked to generate a function that correctly evaluates a prefix notation expression—a classic problem in computer science. Then, all five implementations were compiled and fed back to the LLMs, asking them to rank the five versions from best to worst based on the code review criteria they created in the first experiment.

This setup created a double-layered challenge:
How well can each LLM write structured, correct, and maintainable code?
Can the LLMs objectively evaluate their competitors’ work? Or will they show bias toward their own implementations?
The results? Some clear winners, some biased reviewers, and some models that were more self-critical than expected.
Breaking down the rankings
After compiling all the rankings, I calculated the average score each LLM received. The lower the score, the better that model performed in the eyes of its peers.
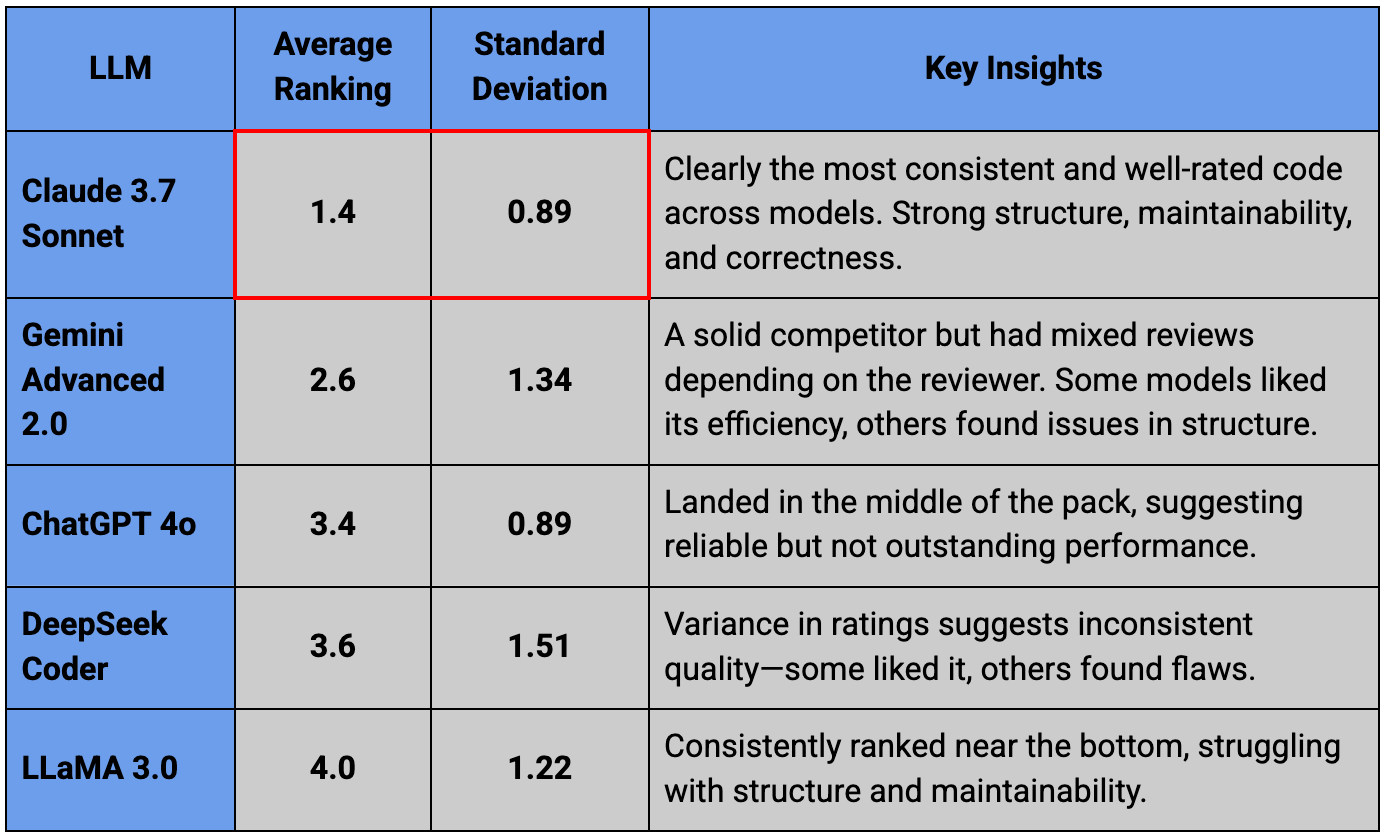
The rankings alone don’t tell the full story. The feedback each model provided about its competitors offers an even more insightful look into how LLMs evaluate code. Here’s a snapshot of some of the feedback each LLM provided to the 5 version of th prefix calculator implementation
Claude 3.7 ⭐⭐⭐⭐⭐ (5/5)
Modular and Extensible: Uses a PrefixCalculator struct with separate methods for tokenization and evaluation, making it highly maintainable and scalable. Best support for multi-digit numbers, structured design with a tokenizer, excellent error handling, modular and maintainable.
Error Handling: Thoroughly handles invalid inputs, division by zero, and malformed expressions.
Readability: Well-structured code with clear separation of concerns and meaningful method names.
Recursive approach may cause stack overflow in deep expressions, slightly more complex than others.
Gemini Advanced ⭐⭐⭐⭐½ (4.5/5)
Stack-Based Approach: Uses a stack to evaluate the prefix expression, which is efficient and easy to understand.
Error Handling: Covers basic errors like insufficient operands and division by zero.
Readability: Code is straightforward but lacks the modularity and extensibility of the top two. Uses helper functions, efficient stack-based approach.
ChatGPT (Ranked 3rd) ⭐⭐⭐ (3/5)
Stack-Based Approach: Uses a stack to evaluate the prefix expression, which is efficient and easy to understand.
Lacks modularity, no separate token validation functions
DeepSeek (Ranked 4th) ⭐⭐⭐ (3/5)
Recursive Approach: Uses recursion to evaluate the prefix expression, which is elegant and easy to understand.
Error Handling: Catches edge cases like division by zero, invalid tokens, and malformed expressions.
Readability: Code is clean and well-organized, with helper functions for clarity.
LLaMA 3.0 (Ranked 5th) ⭐⭐ (2/5)
Basic Implementation: Uses a stack-based approach but lacks modularity and thorough error handling.
Readability: Code is simple but less structured compared to the top three.
Error Handling: Handles division by zero and invalid tokens but misses some edge cases.
These rankings align with my own analysis, which found Claude’s implementation to be the most structured and maintainable, while LLaMA’s code lacked robustness in several areas.
Did LLMs overrate themselves?
One of the most revealing aspects of this experiment was whether LLMs were biased toward their own code. The short answer? Yes, some were.
DeepSeek, for example, rated its own implementation second, which isn’t unreasonable—but other models placed it lower due to its inconsistent style and recursion-heavy approach. Meanwhile, Claude’s self-ranking closely matched the peer rankings, suggesting a more objective evaluation.
This indicates that some models are better code reviewers than they are code generators—and vice versa.
Did LLMs hallucinate?
No, not exactly, but some provided in accurate feedback including to their own code. For example, ChatGPT incorrectly flagged its own implementation (and others) as lacking the ability to handle multi-digit numbers, which is incorrect. I had to prompt the LLM to point it to this error

Key takeaways
Last week we learned that DeepSeek was the preferred LLMs for code reviewing tasks, based on an evaluation by its peer LLMs. The survey I sent out also validated this outcome. Humans and LLMs prefer DeepSeek to review their code :)
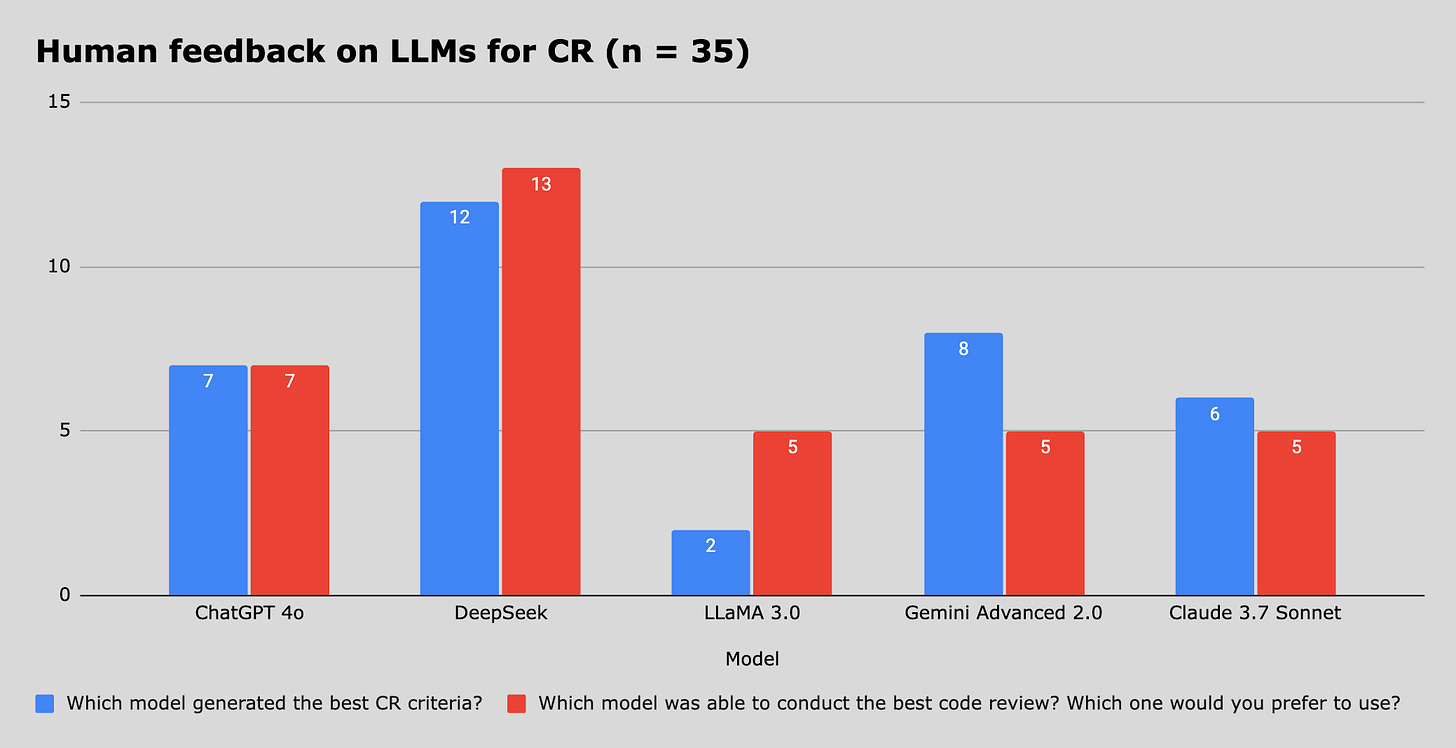
Claude 3.7 Sonnet is the best overall performer, both in writing and evaluating code. If you’re looking for an LLM to assist with maintainable, high-quality engineering work, it’s the top choice.
Not all LLMs judge their own work fairly. Some models overrated their own implementations, while others were more even-handed.
Trust yet verify LLMs; they can still hallucinate or give incorrect recommendations.
