
Battle of the LLMs: Evaluating LLMs as code reviewers


A year ago, GitHub Copilot was the best AI-powered assistant a developer could get. It felt like magic at first—code autocomplete that worked well enough to be useful, even if it had a tendency to hallucinate, get stuck in repetitive loops, and misunderstand broader context. It was helpful, but it was never quite enough. You could feel the ceiling on its capabilities, and in fact, that is reflected with our experience at StrongDM, using Github Copilot about one year ago.
Is Github CoPilot effective?

It’s been about 90 days since we added a Github CoPilot license to every member of my software development team. When CoPilot was first introduced, I wanted to assess its impact on the team. Would it yield to more or better code? Would the engineering team be happier or more productive with this novel tool?
Fast forward to today, and Copilot feels almost primitive compared to the latest wave of AI coding tools. The field has evolved at an astonishing pace. LLMs are no longer just glorified autocomplete—they’re becoming fully-fledged engineering collaborators. Take Cursor, for example. Instead of just completing code, Cursor acts as an agent, iterating, debugging, and even proposing refactors in a way that actually feels context-aware. And it’s not alone. LLMs today are being fine-tuned for specific coding tasks, trained on massive repositories of open-source software, and integrated directly into development workflows with a level of fluidity that wasn’t possible a year ago.
t’s clear that autocomplete isn’t the future—agency is, I think. The real power of modern LLMs isn’t just in suggesting the next token; it’s in their ability to step back, analyze, and provide meaningful feedback. And that’s what we’re here to test today.
Are agents a better fit for AI in software development?

In a previous post I talked about how many members of my software development team at StrongDM found little value in using Github CoPilot. Since then, I have received a lot of feedback which ranges from others finding CoPilot, and more generally GenAI code-completion products, immensely useful, to those that found them to be a waste.
The real test: Can LLMs code review like a senior engineer?
If LLMs are going to be real engineering assistants, they need to do more than just fill in blanks. They need to think. They need to critique, refine, and evaluate code in the way a strong human engineer would. So today, we’re running an experiment.
We’re going to pit five of the best LLMs against each other—not to see which one writes the best code, but to see which one thinks the best.
The challenge is simple but revealing: Who is the best AI code reviewer?
To find out, I designed a two-part test. First, we asked each LLM to define what makes a good code review—essentially, to generate a rubric for evaluating code quality. I selected what I thought was a thorough and decent set of criteria and then moved on to the next stage of the test. The selected review criteria is shown below.

With the code review criteria defined, I fed them all the same piece of code and asked them to review it based on those criteria. The code I fed each LLM was code I very quickly put together to implement a very primitive prefix calculator. I implemented it in golang in two ways; once via recursion and another using a stack. It lacked tests, any sort of validation and didn’t support dealing with multi-digit numbers (or -ve values for that matter). Quick, dirty and hacky code.
The real twist? Each LLM was also tasked with ranking the others' reviews, including its own. The contenders in this battle:
ChatGPT 4o (OpenAI)
DeepSeek
LLaMA 3.0 (Meta)
Gemini Advanced 2.0 (Google)
Claude 3.7 Sonnet (Anthropic)
Each of these models has its own strengths. Some are optimized for reasoning, others for speed, others for sheer volume of training data. But which one actually feels like a competent senior engineer when reviewing code?
The ranking per LLM is shown in the table below. Each model rated itself and the other 4, across a 1-5 rating, where 1 is best and 5 is worst. The diagonal cells show each model’s self-assessment. The average row is simply an average ranking of the model across its own rating and that of its peers.
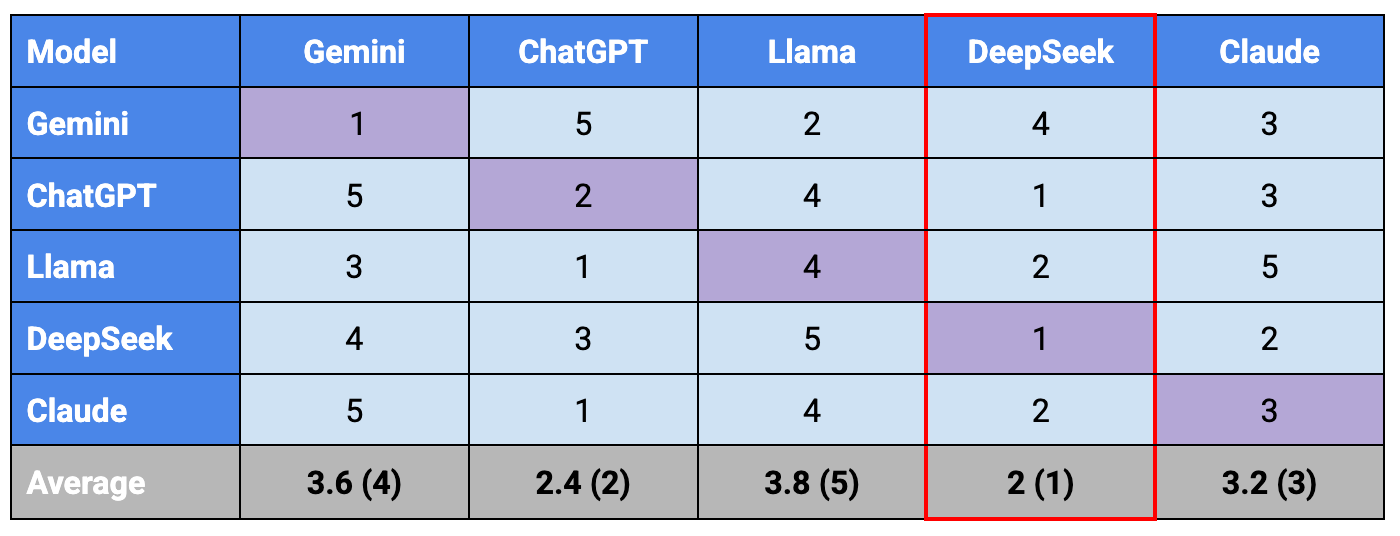
A few observations from the above:
DeepSeek and ChatGPT seem to be universally (scoped to a universe of 5 LLMs) regarded as better than the other 3 LLMs in this task. Side observations, DeepSeek’s output at times was eerily similar to ChatGPTs 🤔
Gemini has an inflated self-worth? It rated itself highest, yet the best it got from its peers was an average rating.
Gemini also seems to be polar opposite to its peers. It rated both DeepSeek and ChatGPT the lowest at performing this task whilst its peers tended to rate those two highest
Llama is not particularly good at this task. But at least it's aware of that limitation - see its own self-assessment 😊
Obviously all the models were able to point out the very many flaws in my code from the obvious ones to some more subtle ones. The difference, at least to me when reading them, was more stylistic and tone vs actual content. Some models excelled at summarizing and providing actionable feedback in the form of recommendations. Oftentimes those would be in priority order too. I also found that the LLM ranking was aligned with how I ranked these models too. I preferred DeepSeek and ChatGPT over the rest.
In summary, do I believe that this generation of LLMs can craft code review best practices and also help (human) software engineers with code reviews? Yes and yes.
Lastly, I shared all the model outputs for both review criteria and each model’s CR for my input code on Github here. I also have a very short survey to get human input on which models is the best for CRs. The models have been anonymized in my survey. Please take a minute to fill it out.
I will share the responses in my next post, which will cover another LLM battle: which one is better at writing code.
The main problem right now is the ambiguity of English creates a bunch of places where code generation can be inconsistent when code is generated. I have been looking into function calling to try to get specifications that can be committed into the repo. Something like TLA or Fizzbee would work. It mostly comes down to defining communicating state machines, (maybe via a BNF grammar), and having temporal logic. I was trying out scraping the conversations to parse facts into Prolog, and SQL. Most model checkers are based on LTL or CTL. But the main thing is if you can agree on consistent specifications; then what code gets generated should be acceptable via meeting the spec. Often, we write code to jump around writing specifications.