
The sad state of software testing
Subjective, ad hoc and lacking basic scientific rigor


Testing software is, in my experience, both one of the more critical and under looked aspects of software development. It is estimated that anywhere from 30-50% of a software project’s effort is dedicated to testing (source: The Economics of Unit Testing). The obvious rationale for spending that much effort on testing is to validate that the software being developed adheres to a specification and delivers its intended functionality.
There are, however, more benefits to testing, which I argue are more valuable than the verification and validation benefits. A well tested code-base should be easier to build on than one that isn’t. Therefore, a well tested code-base should increase developer productivity. A well tested code-base should be easier to maintain than one that isn’t. This in turn results in fewer customer escalations and support incidents. Finally, a well tested code-base should suffer from fewer bugs than one that isn’t and when bugs do appear, they should be easier to fix in a well tested code base.
But what is well tested code? And why did I use should not is?
We’ll dig more into these questions in a bit, but first a mental model to illustrate why this question is critical to answer. Consider the 2x2 shown below that plots the relationship between test benefits and efforts. The benefits include the obvious validation & verification and the maintainability, reduced support costs..etc. The effort is the time and resources spent in testing a code-base. The ideal quadrant is the top leftmost one: max benefit and min cost. I argue that the second one is the top rightmost and that the bottom two should be avoided.
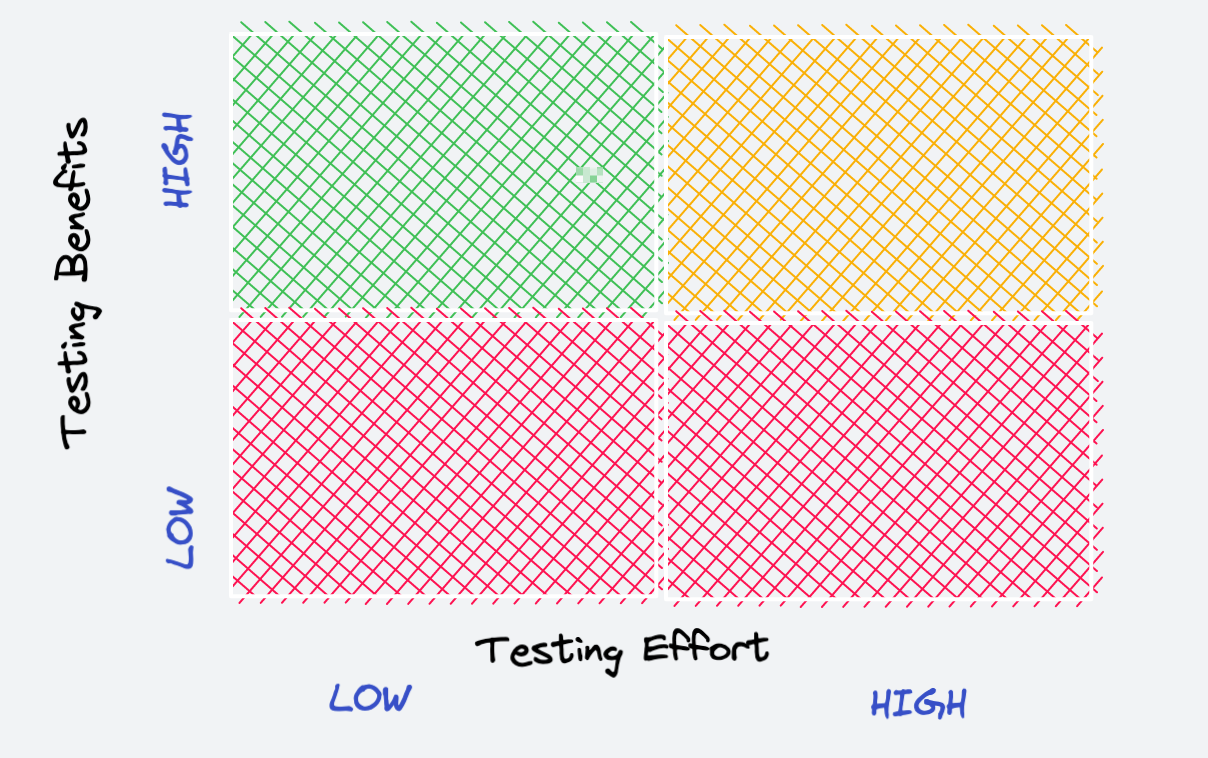
I offer the model above not to debate which quadrant one should optimize for. The point I am making is that we have no manner in knowing let alone optimizing this problem. As far as I can tell, there doesn’t appear to be a model that can measure the causal relationship between testing and maintainability or any of the other benefits mentioned above. As a result of this lack of measured causality, trying to answer a question as simple as “is this code well tested” is at best done subjectively.
There doesn't appear to be a manner in which one can objectively assess the health of a code-base to determine whether more testing is needed and where. As an industry we tackle this problem in an ad hoc and brute force manner and we apply a bunch of heuristics to help us feel good about our testing efforts. Efforts, not benefits.
The closest I have come to encountering a model for the causal relationship between testing and its benefits like maintainability is in this paper “Test Code Quality and Its Relation to Issue Handling Performance” by Athanasiou et al.
The paper offers a test quality model that is based on simple measures which include the following:
Code coverage
Asserts density (asserts : LOC)
Asserts: Cyclomatic complexity
tLOC : pLOC
The authors then proceed to measure the correlation between testing and defect resolution time, throughput and productivity. The model they present shows strong correlations between testing:throughput and testing:productivity.
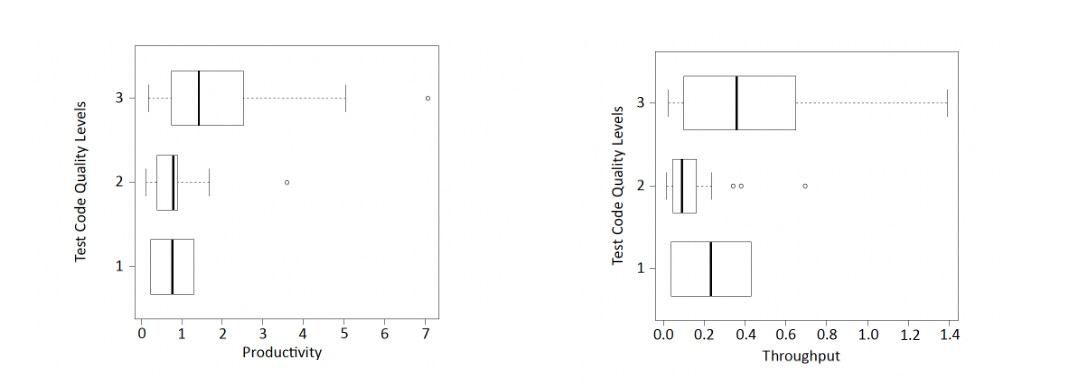
I am not going to poke holes into the model, of which there are many. I will simply point to this: correlation is not causation, which the authors proceed to warn us about.
“Establishing causality: The experiment’s results are a strong indication that there is a relation between the test code quality model’s ratings and throughput and productivity of issue handling. However, this is not establishing causality between the two. Many factors exist that could be the underlying reasons for the observed relation, factors which we did not account for.” Source: Athanasiou et al
We’re now back to where we started. We spend significant time and energy on testing software, yet have no reliable manner to answer the most basic questions on the efficacy and thus benefits of these efforts. As an industry we are left to an alchemy of simple statistics (code coverage, tLOC:pLOC), code smells and a healthy dose of subjectivity and somehow connect those to benefits. Our efforts are also a hodgepodge of unit tests, end to end tests, manual testing and so on. Again, all entirely subjective with no reliable manner to measure efficacy or optimize when and how to test.
Maybe a casual model doesn’t exist for a reason and maybe the efforts we do now are “as good as it gets.” Even the authors of the paper I quoted acknowledge that much.
“What makes a good test? How can we measure the quality of a test suite? Which are the indicators of test effectiveness? Answers to these questions have been sought by software and reliability engineering researchers for decades. However, defining test effectiveness remains an open challenge.” Source: Athanasiou et al
I am skeptical and I hope more effort is dedicated to this topic, both in academic research and practical tooling/products. I mean the hardware folks have tools that just do that, why can’t software having something - anything - similar?
Until then, what we are left with is honing our objectivity through trial and error, tribal knowledge, best practices and learning from others who have done a remarkable job in this domain.
I will be attempting to do just that in my next post by interviewing one of the very best systems software engineers I worked with on this topic. Neal Fachan has an uncanny knack at both building and testing complex software systems. Until then, I cannot recommend this talk from Arista’s Ken Duda enough.
One more thing: If you know of tools, products, papers or anything else that might be relevant to this topic, please send them my way.
I look forward to the interview with that Neal guy!
I think getting testing right is a fundamentally hard problem with lots of trade-offs, which requires judgment, which is one of the key reasons why senior engineers are paid so well.
You could spend unlimited time polishing unit tests to check every edge case (and some simplistic XP practictioners would be thrilled) but then the slightest interface change requires reworking all those tests. Conversely you could rely only on manual integration tests so that every change requires an expensive custom testing pass and your build-deploy cycle grinds to a halt.
On a different axis you could write extremely ugly chaos-style integration tests with lots of layer violations to make sure your code does the right thing in response to various failures, and it might be 10X easier and more effective to just have a TLA+ spec to verify high-level correctness and use a model-checker to find weird bugs.
Making testing good and cheap requires very experienced engineers who know how to design and modularize the system for good testing -- if that was easy to automate, then in some sense the project itself would be amenable to automation (and you could save yourself the highly paid engineers).
I think 3 critical principles are (a) you should have unit tests with fairly high code coverage, (b) you should have easy-to-run smoke tests of the entire system that validate basic use cases to make sure all the parts are integrated well, and (c) tests should be run regularly and failing tests should be taken seriously. In my experience it's a pretty bad antipattern not to do those 3 things.
Great post as always! I guess on measuring the efficacy of testing as a whole, it's sort of hard to know besides maybe lack of incidents or reduced latency?
A lot of tooling works in a testing environment and is measured at the time of testing. For example, developers using AtomicJar can test in a containerized environment, have a fair amount of certainty that it works and then deploy. Of course, there can always be issues but in and of itself, AtomicJar's success sort of validates the test right? Curious on your thoughts on what you'd look for in measurement across all tests.