
So, you want to build ML models...
How strong are your data jujitsu skills?


A few weeks ago I hosted a series of roundtable discussions with a group of engineering leaders from Atomico’s portfolio companies. The theme of these discussions was on data, specifically the challenges of data in an AI company. The topic is admittedly broad and open ended, but it is an important one nonetheless.
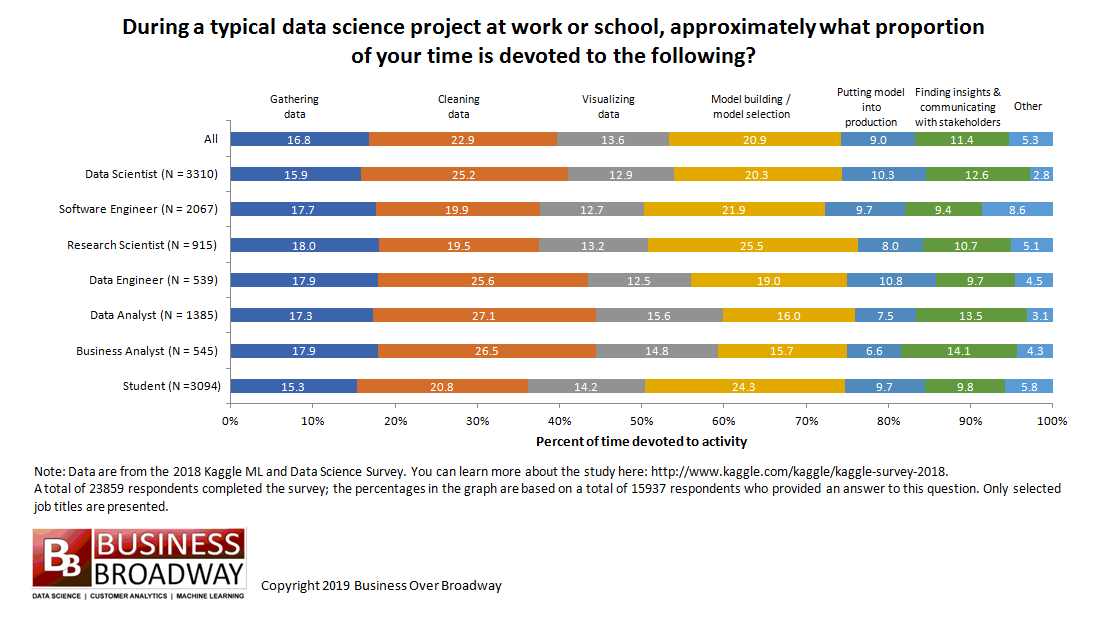
A significant portion of building AI, or to be more specific machine learning (ML) models, is centered around data. ML models are mostly concerned with getting data, cleaning it, transforming it, visualizing it and finally using it to build models. A recent survey by Anaconda revealed that the time spent with data manipulation (or wrangling) represents about 65% of the total of time spent by ML/data scientists. These figures are consistent across other surveys as well. Dealing with data is a significant portion of how ML/data scientists spend their time.
{kind=link}
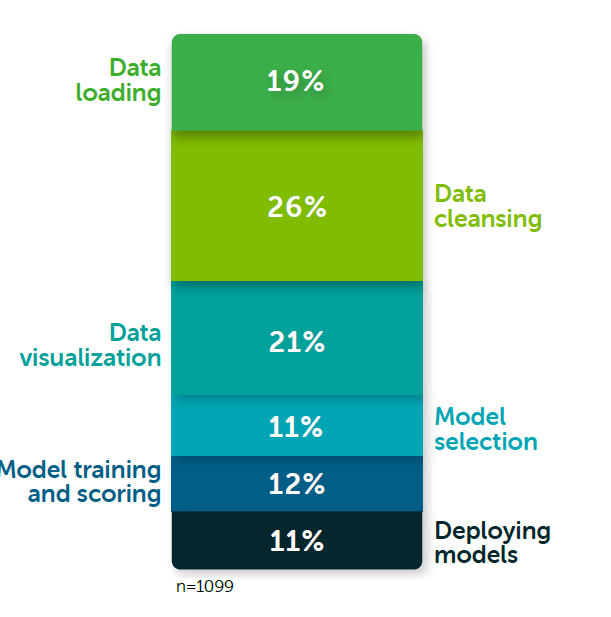
Source: 2020 State of Data Science: Moving From Hype Toward Maturity.”
Over the next few blog posts I will go over a series of linked topics. These series of posts will be concerned with the overall challenges of data for an AI company, with a simple framework to help guide the conversation. The series of posts will cover the overall framework that guided our discussions along with a dive into each of the 3 major data activities for building ML models.
The (simple) framework we used in our discussion was centered around 3 data activities, which are illustrated in the diagram below. These are sufficiently broad and cover the major data activities that an ML product or team will undertake. It is worth nothing that the scope of this discussion is limited to model building, or training, rather than the full life-cycle of a model up to deploying to production. The latter will be covered in future posts. The first series of these posts will cove the data collection step, which is the first step outlined in the “framework” below.

ML models are data optimization algorithms. A model tries to fit a curve over a series of data - the training dataset - in an attempt to minimize or maximize a function, typically known as a cost function in ML parlance. The linear regression algorithm is a good example. It performs an optimization process to find a set of weights that minimize the sum squared error on the training dataset. More on that topic and on how ML models “learn” - can be found in one of my previous articles.
It should come as no surprise then that building AI products, more specifically ML models, requires a significant amount of data. Not only do you need a large dataset to build the initial model with, but you will continuously need more data to fine tune your models to ensure that they are able to generalize on new input - to tackle the long-tail of AI
The data collection problem can therefore be broken down into two distinct phases. The first phase is getting the data you need to build your initial model. I call that the bootstrapping problem. There are numerous ways to get the initial dataset needed to bootstrap a model. The second phase is concerned with getting data to continuously train and improve on your model. Models are like gardens, they need constant grooming.
There are numerous data sources available for the bootstrapping phase. You can find data online either freely available or for purchase. For example, Kaggle hosts a variety of datasets as does AWS. Once you have a model running another data source comes in play. The data exhaust from your model becomes a source of training data. One particularly useful piece of data is the input data to your production model. That data can be used to train newer versions of your models.
There are two main challenges across both phases of the data collection phase: ground truthing, or labelling and data mapping. An example might help illustrate both of these.
Suppose that we are building a model to recognize pictures of cats. We go out and obtain a dataset containing thousands of images of cats and other animals, say dogs. If we are lucky, the dataset that we obtained will be already pre-labelled. This means that pictures with cats are clearly marked as such and similarly for ones with non-cats, dogs in our case. In the case of our dataset, the image filename identifies whether the image is that of a cat or dog, as shown below.

Unfortunately, clearly labelled datasets are the exception and not the norm. Furthermore, the labels can get quite complex, depending on the nature of your model. Consider the case where we want to extend our cat recognition model to not just recognize cats (i.e. classification) but to also highlight the location of a cat in an image (i.e. localization). This can be done by enclosing images of cats with a bounding box as shown below.

Source: Medium
Suddenly our training dataset which only identified whether or not the image is that of a cat or not is inadequate. Our training data lacks the bounding boxes indicating the location of a cat in an image. We have to enrich our training data to include bounding boxes around images of cats, to help our model to both classify and localize images of cats. That is typically a manual process which requires humans to label this data. This is where labelling tools like V7, Hive, Labelbox, AWS SageMaker GroundTruth, CentaurLabs to name a few come in play
Let’s add another twist to this tale. Our model is now able to both classify and localize cats. However, the business now requires us to enhance it by adding new features. Our model should differentiate between kittens and adult cats. It should also classify cats into one of Siamese, Persian, Bengal, American Shorthair, Turkish Angora or Other. Our training dataset now needs to be enhanced yet again. We can no longer rely on the presence of the “cat” string in the filename to help us with the classification of the images, we know have to add more metadata to our training dataset.
Our cat recognition model is taking the world by storm. As such, the business requires us to expand into Asia and asks us to augment the model to classify cats that are commonly found in Asian countries. Our initial training dataset was heavily biased towards cats frequently found in Western countries. We are able to obtain additional data to help our model generalize against Asian cats, but the data is quire different than our existing training dataset. The data we obtain consists of thousands of JPG images and a CSV file. The file contains metadata about every image, as shown below.

Observe how the structure of this training dataset is quite different than our initial one. Our initial dataset encoded the presence of a cat in an image in the image filename, while our Asian dataset relied on a CSV file for the classification of images. We now have to adopt our training pipeline to “understand” both data models or merge them into a common one. We now suddenly contemplating ETL, Airflow and transforming our various training datasets into a common taxonomy.
Additionally, the images we obtained from our Asian dataset were of a different size than the ones we previously had. We now have to harmonize both sets into some standard image size that our ML models will train on. We also noticed that some of the images in this dataset didn’t we not applicable to our domain - cats. There were thousands of files containing images of single cell protozoa. Those were very likely included erroneously in the Asian dataset that we obtained. Hint: always visually inspect your data!
Before we know it, what started out as a simple task that required limited disk and compute capacity is now a complex web of transformations, mapping, labelling and visual inspection of the data. It’s not unreasonable that the stack we will end up building might resemble the one shown below. Note, that the storage and training layers will be covered in the next post along this series. Those will also add different requirements and tools to our stack.

The challenges that I highlighted in this article appear simplistic due to the nature of the problem: recognizing images of cats. However, these challenges can get quite complex when building “real” models. They are exceptionally harder in domains where the data is difficult to get, lacks standards resulting in painful schematic and semantic mappings across datasets. The challenge is further exacerbated with domains that are characterized by having a very long-tail of data distribution like health care; a domain I am quite familiar with.