
Classification models & thresholds
Which threshold to chose and how?


Classification models are a subset of supervised machine learning . A classification model reads some input and generates an output that classifies the input into some category. For example, a model might read an email and classify it as either spam or not - binary classification. Alternatively a model can read a medical image, say a mammogram, and classify it as either benign or malignant.
Classification algorithms, like logistic regression, generate a probability score that assigns some probability to the input belonging to a category. This probability is then mapped to a binary mapping, assuming the classification is binary (malignant or benign, spam or not spam). In the previous spam example, a model might read an email and generate a probability score of 92% spam, implying that there is a very high chance that this email is indeed spam. For probability scores on either end of the spectrum, the mapping is quite obvious. A score close to 0 implies the email is very likely not spam, whilst one closer to 100 implies that the email is very likely spam. However, the mapping decision isn’t entirely obvious in many cases. Consider a score of 58%, should that be classified as spam? Similarly, should a score of 32% be classified as not spam?
In order to map the output of a logistic regression, or similar probabilistic classification models, into a binary classification category, you need to define a classification threshold. This threshold represents the decision making boundary. In the previous example of our spam classifier, values above this threshold will be mapped to the spam category, whilst those below or at the threshold will be mapped to the not spam category. The question is how do you choose this threshold and what does this choice imply.
Before we can answer this question, we will need to take a slight detour to understand how to measure models. A model like ours that classifies emails into either spam or not spam can be evaluated across these 4 measurements: true positives, false positives, true negatives and false negatives, which are all defined in the 2x2 below. Green quadrants represent the agreement between reality (truth) and the model (prediction), while red represent discordancy.

Using the above 4 measurements, we can derive an additional two, which are instrumental in evaluating a model’s performance and ultimately how to choose the threshold.
True Positive Rate (TPR): This measures the degree to which the model was able to correctly predict positive cases. This is a function of the model being able to correctly identify True Positives relative to the sum of True Positives and positive cases that the model incorrectly classified as negatives; False Negatives. Just to add to the confusion, this measurement is often times referred to as Sensitivity or Recall

True Negative Rate (TNR): This is the converse of the positive case. It measures the degree to which the model was able to correctly identify truly negative cases. This is a function of the True Negatives relative to the sum of True Negatives and cases that the model incorrectly classified as positives; False Positives. This measurement is also referred to as Specificity

Let’s put these measurements in play now using an illustrative example. Let’s assume that we have a model that will classify 10 email messages as either spam (positive) or not spam (negative). The ground truth of these 10 emails is shown in the first row of the below table. Of the 10 emails, 5 are truly spam and 5 are not. The model generates a probability score for each input email, shown below on the second row. The last five rows map this probability score into a binary decision - spam or no spam - using 5 different thresholds. The first threshold is 0.5, meaning if the mode’s probability is > 50% then the email will be classified as spam and anything below that score will be classified as not spam. The other thresholds are 0.3, 0.8, 0.0 (100% spam) and 1.0 (100% no spam). The latter two thresholds are extreme cases. Finally, cells marked as green illustrate True Positives and True Negatives, while ones in red illustrate the False Positives and False Negatives.

The table below shows the 4 measurements earlier defined along with the TPR and TNR for each of the three thresholds used. Notice how the TPR and TNR are affected by the threshold change. Also note the inverse relationship between sensitivity (TPR) and specificity (TNR). When one increases, the other decreases. Finding the right threshold is a tradeoff between these two measurements.

This makes intuitive sense. A model with a very high threshold (0.8), will err on the side of classifying most emails as not spam. Conversely a model with a very low threshold (0.3) will be quick to classify most emails as spam. Both are correct, what ultimately matters is the intended use of the model and the implications of these thresholds.
Imagine if the model with the 0.3 threshold is actually deployed to filter out spam on your email provider. This model will be very aggressive in classifying most emails as spam. The consequences of this approach would be you missing out on non-spam emails which would end up in your spam folder.. You’d have to regularly check your spam folder to see if it contains non-spam (false positives) messages. That might render a poor user experience. Alternatively a spam filter that has a very high threshold (0.8) might result in an inbox full of spam. That’s also not a great user experience.
We need to introduce one more concept before we are able to answer our original question: how to pick the “correct” threshold. That concept is the Receiver Operator Curve, ROC for short. The ROC plots the sensitivity and specificity (in reality it plots 1-specificity) of a model at various thresholds. This is similar to the earlier example, which showed sensitivity and specificity for a model along 5 distinct thresholds. An illustrative ROC for various models is shown in the diagram below. Each curve represents a classification model

By Martin Thoma - Own work, CC0
The curve is useful to understand the trade-off between TPR and FPR which is (1-TNR) for different thresholds. Additionally, the area under the curve (AUC), provides a single number to summarize the performance of a model. A perfect model will have an ROC of 1, whereas a model that performs no better than a coin toss (random classifier) will have an ROC of 0.5. The ROC is a useful diagnostic tool for understanding the trade-off between different thresholds and the AUC provides a useful number for comparing models based on their general capabilities.
Almost there, I promise!
The optimal threshold is the point that maximizes the TPR and minimizes FPR. We can sort of eye-ball it on the blue curve above where the TPR is ~0.65. Rather than eye-balling, we can also pick the threshold that maximizes the geometric mean of the specificity and sensitivity.

The geometric mean method to identify the optimal threshold, might not actually be the optimal point you want to use (pun intended). There could be some undesired consequences with simply picking up the point that maximizes TPR and minimizes FPR. Consider the case of a model that classifies criminals into ones that should be sentenced to death or not - I hope such a model is never developed, but bear with me. You probably want to err on the side of minimizing false positives, because the consequences of a false positive are quite adverse: your model would send an innocent person to their death. The balancing act you will have to play is choosing a threshold that reduces false positives whilst also yielding a reasonable TPR. The diagram below depicts this.
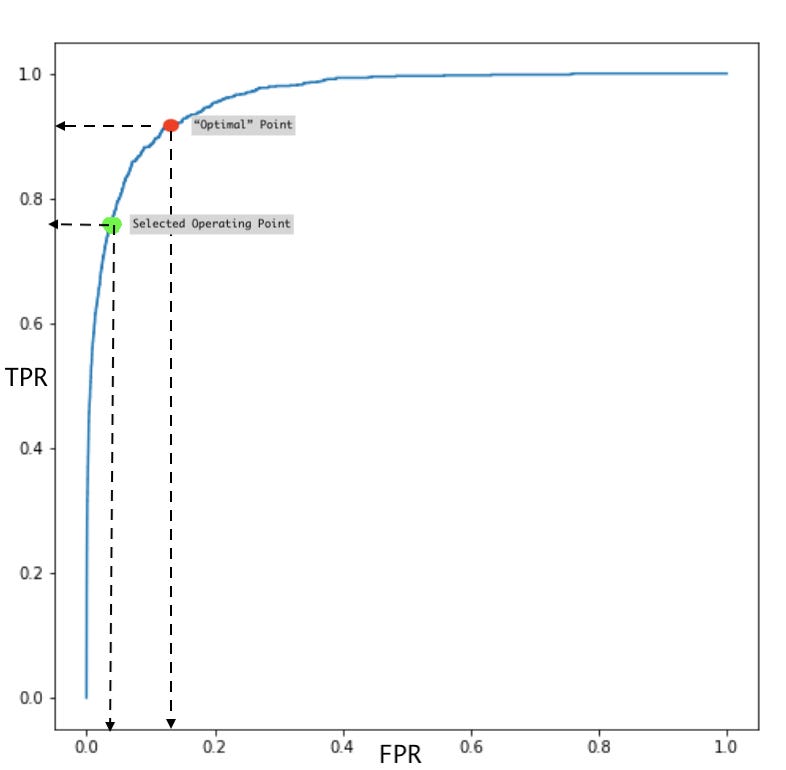
Using the geometric mean method would yield a threshold shown by the red dot above. This threshold would result in a FPR of about 18%. Alternatively selecting a lower threshold along the ROC curve (green dot) results in a FPR of about 2%. The obvious tradeoff here is by selecting the threshold at the green point, the TPR is reduced by about 10%, but that’s probably a good tradeoff given the consequences of false positives in our model.
So the answer to what threshold to use is after all “it depends” :)
Hey,
Great post as always. Minor typo in last few paragraphs you switched the FPR acronym with FRP.
Thanks for sharing!