
AI's Coefficient of Satisfaction
Can't get no satisfaction

👋🏽 Welcome to Brick by Brick. If you’re enjoying this, please share my newsletter with someone you think will enjoy it too.👇🏽
Most AI products are primarily concerned with making inferencing decisions. An AI model receives some input which will run through the model resulting in some decision, oftentimes called a prediction or inference. Depending on the nature of the AI model, the precision of the decisions it makes can have profound effects on its usage and ultimate success.
Consider a recommendation engine, perhaps one that recommends what movies to watch based on your viewing history. The AI model in this case is making a predictive decision based on your own viewing history. We’re all fairly accustomed to these recommendation engines on sites like Netflix (movies) and Amazon (products). We also find similar recommendation engines at work on popular social networks that decide what news I get to see, which ads are targeted to me and so forth. As an example, the figure below shows what Netflix recommended based on my viewing history, in this case watching the Senna documentary.

Similarly, autonomous vehicles make predictive decisions based on observations from their surroundings. An autonomous vehicle is constantly processing data from sensors, using that to drive the vehicle. Should the car accelerate? Should it change lanes to avoid an object veering from the nearby lane? Should the car decelerate or stop to prevent it from hitting a pedestrian and so on. All of the decisions are made in real-time by AI models embedded in the car constantly reading sensory data and responding in real time.
Models will make mistakes, hence their name: models. There are many reasons for why this is inevitable, but perhaps the most common one is in the difference between the data a model was trained on and the data it “sees” in reality. A model’s imprecision will have some impact on the end user. That impact could be negligible or profound, depending on the model and what it does. I call that effect, the coefficient of satisfaction of AI, or CoS for short.
In the case of recommendation engines, the CoS is negligible. I will not be particularly displeased if my Netflix recommendations aren’t to my liking. Similarly, I won’t be wowed if they are. The same applies to product recommendations on Amazon or what Facebook decides to display on my news feed. In both cases, whether the recommendations are “correct” or not, my reaction is almost indifferent. There’s very little downside or upside to being correct/incorrect, up to a point. If all the recommendations are wrong, and continue to be wrong, I might start having a negative reaction to the product. I expect the recommendations to be faulty, but also expect them to be directionally correct.
Now consider the decision-making impact of AI in autonomous vehicles (AV). A model making the correct decisions, meaning navigating the vehicle safely, is not met with delight from the human behind the wheel. The model is expected to make the right decisions - that’s the promise of AV after all. The converse is not true. An AV model making incorrect decisions can endanger the lives of passengers, other vehicles and pedestrians alike. The impact of a wrong decision can be profoundly negative. For classes of products like AV, the upside of a good decision is negligible but the downside of a bad one can be substantially negative.
One can view the CoS along a continuum ranging from a fairly large negative number to a small positive one. AI products will have different ranges along the CoS continuum. The range will be representative of the impact their decision - good or bad - make on the end user. The diagram below illustrates this point using the AV and Netflix as examples.

An AV-like class of products will have a CoS that ranges from a relatively large negative number to 0, or perhaps slightly above that. In the example above I used the range [-100, 0] to capture the CoS for AV. On the other hand Netflix-like recommenders have little to no downside and a fairly limited upside. I used a CoS range of [-1,1] for these types of products.
The exact range or value of this coefficient isn’t what I care about - my values are for illustrative purposes. There is no “science” behind the ranges I propose. Rather it is the impact that this coefficient makes both on the end users and the developers of AI products.
It is worth noting that a product’s CoS can impact its continued usage. The relationship between usage and CoS can be expressed according to the following equation, where σ represents the CoS. Again, no “science” here, this is mental model, with some basic maths
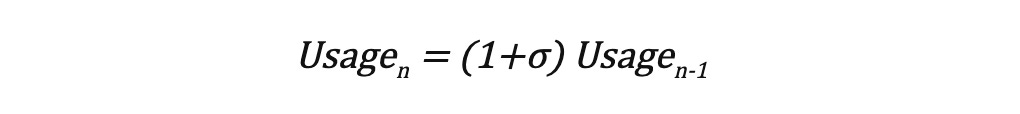
Products with a CoS in the [-1,1] range like Netflix’s recommendation engine will not see a dramatic impact in their future usage. If the recommendations work well, I will still continue to use Netflix, likewise when they don’t perform well enough. There’s additional value in imprecision, namely the model should learn from imprecise recommendations it made and therefore improve. The obvious caveat here is that this should be a balancing act. If I start seeing recommendations that are entirely outside my favorite genres, then the impact will start being negative, impacting my future usage of the product.
On the other hand products with a CoS like AVs have to be very careful, they cannot afford the luxury of being wrong. I won’t shrug my shoulders and simply carry on with my day if my AV runs a traffic light or is responsible for a collision. Similarly, a model predicting cancer or other diseases can have a profoundly negative impact when making bad decisions. A negative prediction can dramatically reduce, or even completely stop, future usage of these products.
There are two major implications for products that fall into this category.
First, these products aren’t truly autonomous. There is always a human-in-the-loop. There’s a reason why a driver is still behind the wheels of autonomous vehicles. Similarly, AI products in the healthcare sector, especially those making clinical decisions, aren’t autonomous. A human - healthcare professional - uses these tools to ultimately make her own decision. We explored this phenomena of AI + humans working together in centaur-like collaboration models.
Second, these products might face hurdles when being adapted to an environment different than the one they were trained under. Environment here is a function of data - the inputs to the model - and particularly the distribution of this data.
Consider the diagram below, which illustrates the distribution of some input data to an AI model. The input data has a very long tail, it is skewed to the right. The AI model was trained on a small subset of this data, illustrated in green below. Anytime data from the untrained - blue - parts of the distribution is fed into the model, there is a chance that the model will not perform well enough. This problem is oftentimes referred to as the long-tail of AI and was covered in a previous post.
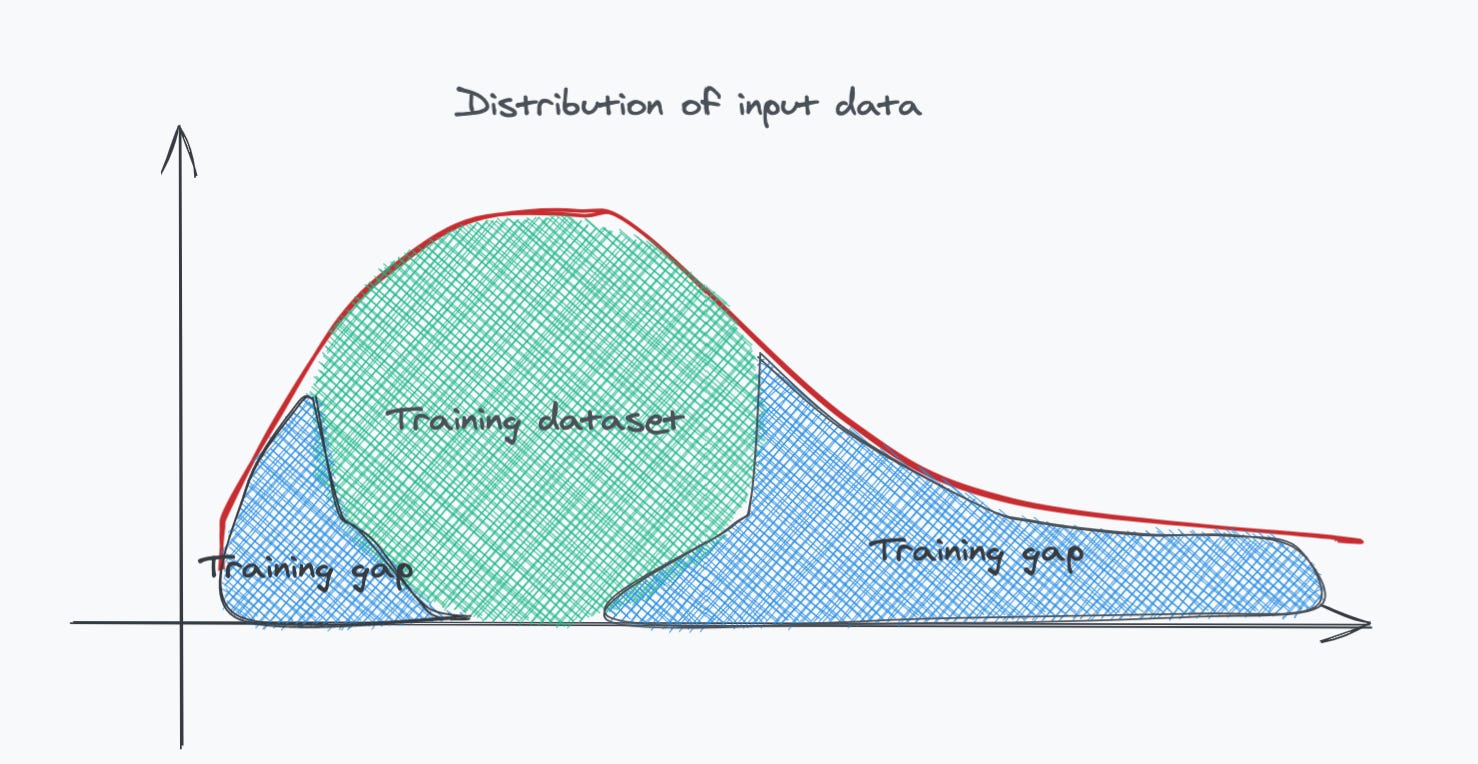
A good example of this problem is autonomous vehicles like Teslas. Tesla’s training has been mostly conducted within a North American and European “environment”. I would posit that a Tesla would utterly fail in navigating the streets of Cairo (see picture below). The model has never been trained on data similar to what it is witnessing on the mad streets of Cairo.

Cairo Traffic. Picture taken January 28, 2020. REUTERS/Mohamed Abd El Ghany
Similar challenges can be found in other categories like healthcare, of which I am quite familiar with. Healthcare AI is susceptible to the wide distribution of patient demographics like age, sex, genetics, race and so forth. Building healthcare AI products that perform well enough on a diverse population requires that the model have been trained on data that represents that population. That can be challenging to do.
In closing, it is worth noting that the intent of the CoS is not to try and measure it, but rather to understand that predictions from AI products can have a significant impact on future usage of these products. And that this impact can vary quite dramatically between different product categories.
Thanks for reading! If you’ve enjoyed this article, please subscribe to my newsletter👇🏽.