
Adventures in hill climbing with AI
How to build generalizable AI products


In a previous article, I outlined my recent experiences with building AI products and their differences relative to traditional software. In the second part of this series, I will take this one step further and discuss how AI products (models) are dynamic entities that constantly need to be optimized along with the implications of this phenomena.
Let’s imagine for a moment that we are working on building a novel AI product. Our product will receive as input an image of a car crash and generate an output decision: whether the car is a total loss or not. One can imagine that this model could be used by insurance companies to make a quick assessment of car insurance claims they receive. They could use our product to quickly classify incoming claims as total losses or otherwise.
There are two parts to our product development efforts which I will focus on today. The first is in the initial data acquisition to help build our product. The second is in getting customers to use out product, which likely will require custom calibration.
During this article I will use the terms AI, ML, model and product interchangeably to represent an artificial intelligence based product - a Software 2.0 product.
Initial data acquisition
Building a model like this requires having a sufficiently large dataset to help train the model with. Training data represents both the data that our model expects to see once deployed, which in our case will be images, along with labels indicating the semantic meaning of each image. In our case, the label accompanying each image will be a binary number, 0 or 1, where 0 indicates that the car in the image is not a total loss and vice versa for 1. Below are a few examples of how this training data might look like.

Images source: Insurance Institute for Highway Safety (IIHS)
Getting this data isn’t straightforward, both in terms of finding it and more critically correctly labelling it. There are typically a few avenues for data procurement: DIY, partner, buy.
You can do it yourself, perhaps by scraping Google or other websites to get millions (most ML algorithms require a lot of data) of car crash images. This assumes image copyrights and these websites allow you to do so. You could partner with entities like IIHS who could give you access to their data set. Finally, there might be car crash data sets that you could buy. These options are non mutually exclusive. Regardless of which ways you used to get your data, you will then have to correctly label it.
Recall, from our previous article, we mentioned that an ML model is akin to training a child to recognize shapes. If the flash cards the child uses are incorrectly labelled, the child will not be able to correctly classify shapes. ML models are the same. Therefore, having correctly labelled data is absolutely critical. You will likely have to develop the in-house capability to correctly label your training data. Doing so, might very well require you to hire people with deep domain expertise on car insurance to ensure that your training data is correctly labelled.
Customer Adaptation
You’ve procured your data, correctly labelled it and have a model that you feel confident will get the job done. Now it’s time to sell your product and get it in your customers hands. In this case our customers will be car insurance companies. Seems to be pretty straightforward, except it isn’t. There are a few wrinkles that will complicate things.
"No plan survives first contact with the enemy" Helmuth von Moltke
Beauty is in the eye of the beholder
Let’s use the image shown below to try and answer a simple question: is the damage to the car a total loss? According to Wikipedia, a total loss is defined as “... a total loss or write-off is a situation where the lost value, repair cost or salvage cost of a damaged property exceeds its insured value, and simply replacing the old property with a new equivalent is more cost-effective”

Image source: Insurance Institute for Highway Safety (IIHS)
That definition makes total loss a relative and not an absolute assessment. For example, insurance company A operating in market M, can deem the car above as a total loss. While another Insurance company B operating in a different market N might not. Perhaps they have very different cost structures, maybe B has access to a highly talented and inexpensive repair labor force whilst A does not.
Drift
Next, let’s consider the image below. The car has witnessed considerable hail damage and is likely a total loss. However, once we input this image to our model, it responds with 0, or not a total loss. What just happened?

Source: Pinterest
It turns out that our training data didn’t have any images of hail damage. Our model simply hasn’t been trained to recognize and assess hail damage. To our model, this image looks no different than a perfect car. Note, one can argue that our model should also generate a third output “I don’t know” to indicate its inability to correctly classify the damage in an image.
This scenario isn’t particularly unusual. In reality, your model is trained on some dataset, but once deployed it might encounter data that it has never seen. Statistically speaking this means that your model is getting exposed to a data whose distribution it is unfamiliar with. In ML-speak this is also known as model drift.
The impact of getting exposed to data from a distribution different from the training data, and potentially having to change the classification rules of a model can have profound implications. First, you will likely have to spend some time testing your product to assess its performance relative to the customer’s environment and her expectations. If the performance is adequate, meaning it meets your objectives along with the customers’ then you can proceed to actually using your products in real production workloads.
However, there will be many cases, especially with recently developed models, whereby you will have to calibrate the model against the customers’ data. In the examples above, you will have to adjust your model to recognize damage from hail and evaluate total loss according to the customer’s threshold. Taken together this implies having to train your model against the customer’s dataset - a lengthy and expensive (GPUs) proposition. It can also dramatically extend your sales cycle.
Hill climbing
We’ve covered the flow to initially develop and release your product, which is illustrated below. You get data, a lot of it, label it and use it to train models ultimately settling on one(s) that meets your business objectives.

Next, you take this model out into the wild, where in all likelihood you will have to customize it to meet customer needs, as shown below.
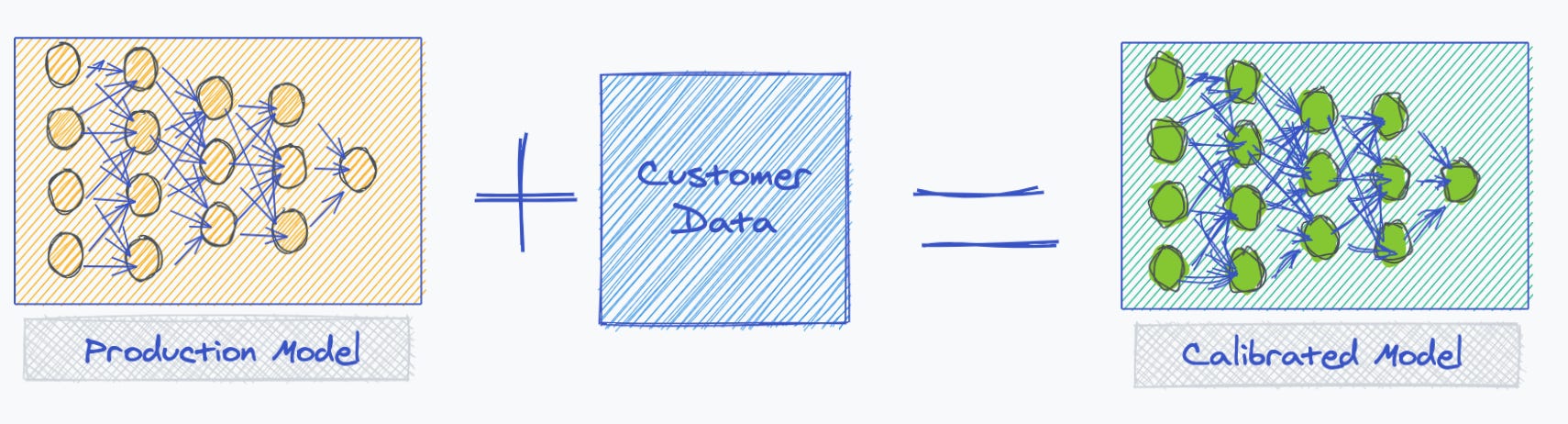
I had previously mentioned that you should view your models as living entities, they need to be constantly trained, much like a child in the early stages of development. One way to do so, is by integrating the model you released with the ones you custom calibrated at customer sites. You want to take the model in the green box above, merge it with the one in the yellow to produce a new version of your release model. You can accomplish this by either merging the customer data with your own training data and building a new model off this combined data set. Alternatively, you can merge both models via an ML technique known as federated learning.
At Kheiron we call this phenomena hill-climbing, which is an overloaded use for the how the term is used in optimization algorithms. We’re used it at the meta-level to attain the optimal model for the widest data distribution. I’m honestly not sure if this is an industry term - AFAIK it isn’t - but I like it and will stick to it. Much like non-AI hill climbing (as in hiking) is hard at first and gets easier as you adapt, your AI products will get better the more data they are exposed to. In the long run, you should not be calibrating at every customer site. If you are, then in all likelihood you are working against an unbounded distribution, or one with very long tails. That will be an uphill battle! A recent Andreessen Horowitz article - Taming the Tail: Adventures in Improving AI Economics - also address this problem. I strongly recommend you give it a read.
And now, back to climbing this hill :)
hill climbing means something completely different and unrelated, and is a critical and basic concept in machine learning